Cloud AI
Our mission is to spread useful AI effectively around the world.

Our mission is to spread useful AI effectively around the world.
About the team
The Google Cloud AI Research team tackles AI research challenges motivated by Google Cloud’s mission of bringing AI to tech, healthcare, finance, retail and many other industries. We work on a range of unique high-impact problems with the goal of maximizing both scientific and real-world impact – both pushing the state-of-the-art in AI (>60 papers published at top research venues over the past four years) and collaborating across teams to bring innovations to production (e.g., 1, 2, 3).
Some recent directions for Cloud AI Research include:
- Developing improved foundation models to solve challenges like hallucinations, data efficiency and generalization.
- Improved adaptation methods, including distillation, task customization, grounding and multimodality.
- Developing large language models (LLMs) for data types that are a high priority to enterprises, such as structured data.
- Building LLMs for tool use.
- Retrieval-augmented LLMs and LLM-assisted search.
- Improved LLM usability through automated prompting, explainability and reliability.
Team focus summaries
Cloud AI researchers develop new large language models for problems that are critical to enterprise customers. These include innovative ways to distill large models while maintaining high performance; improving embeddings of large language models; translating natural language queries to business domain-specific languages like SQL; inventing new large multimodal models that learn from multiple modalities like text, image and structured data; scaling LLM tool usage to large number of tools; and automatic design of prompts for language models.
Explainability is required to effectively use AI in real-world applications such as finance, healthcare, retail, manufacturing and others. Data scientists, business decision makers, regulators and others all need to know why AI models make certain decisions, and our researchers are working on a wide range of approaches to increase model explainability, including sample-based, feature-based or concept-based methods that utilize reinforcement learning, attention based architectures, prototypical learning, surrogate model optimization on all kinds of required data types and high impact tasks.
Data-efficient learning is important, as for many AI deployments it is necessary to train models with only 100s of training examples. To this end Cloud AI researchers conduct research into active learning, self-supervised representation learning, transfer learning, domain adaptation and meta learning.
Cloud AI researchers are looking at ways to advance the state of the art for specific data types such as time series and tabular data (two of the most common data types in AI deployments), which have received significantly less focus in the research community compared to other data types. In time series, we are actively developing new deep learning models with complex inputs – for example, the team’s novel Temporal Fusion Transformer architecture is state-of-the-art in terms of performance across a wide range of datasets. In tabular data, we developed TabNet, a new deep learning method for tabular data that achieves state-of-the-art performance on many datasets and yields interpretable insights.
Cloud AI researchers also conduct research targeting specific enterprise use cases, such as recommendation systems, which play a key role in the retail industry and face challenges in personalization, contextualization, trending, and diversification. We develop recommendation models that support event time-aware features, which captures user history events effectively for homepage recommendations. We also work on end-to-end document understanding which requires a holistic comprehension of structured information of a variety of documents, and recently developed contributed to society by providing a novel approach to forecasting the progression of COVID-19 that integrates machine learning into compartmental disease modeling.
Featured publications
Highlighted work
-
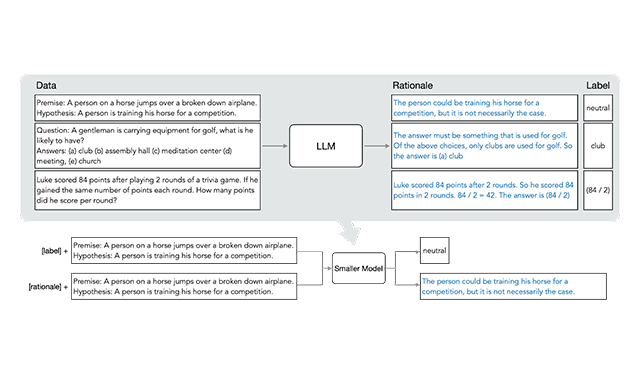 Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model SizesA novel method of distillation that proposes a resource-efficient training-to-deployment paradigm compared to existing methods. The method reduces the size of the training dataset required to curate task-specific smaller models; it also reduces the model size required to achieve, and even surpass, the original LLM’s performance.
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model SizesA novel method of distillation that proposes a resource-efficient training-to-deployment paradigm compared to existing methods. The method reduces the size of the training dataset required to curate task-specific smaller models; it also reduces the model size required to achieve, and even surpass, the original LLM’s performance. -
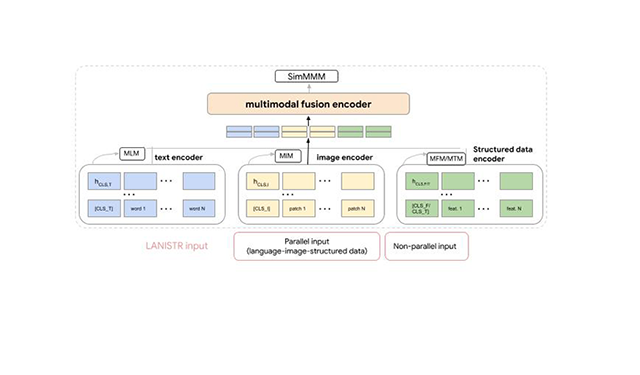 LANISTR: Multimodal Learning from Structured and Unstructured DataA novel method of distillation that proposes a resource-efficient training-to-deployment paradigm compared to existing methods. The method reduces the size of the training dataset required to curate task-specific smaller models; it also reduces the model size required to achieve, and even surpass, the original LLM’s performance.
LANISTR: Multimodal Learning from Structured and Unstructured DataA novel method of distillation that proposes a resource-efficient training-to-deployment paradigm compared to existing methods. The method reduces the size of the training dataset required to curate task-specific smaller models; it also reduces the model size required to achieve, and even surpass, the original LLM’s performance. -
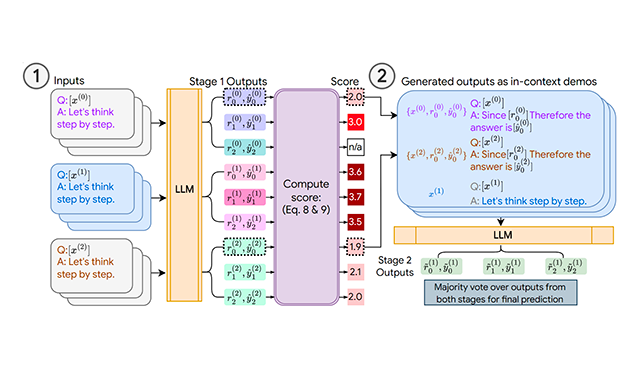 Consistency-based Self-adaptive PromptingConsistency-based Self-adaptive Prompting (COSP), a novel prompt design method for LLMs. Requiring neither handcrafted responses nor ground-truth labels, COSP selects and builds the set of examples from the LLM zero-shot outputs via carefully designed criteria that combine consistency, diversity and repetition.
Consistency-based Self-adaptive PromptingConsistency-based Self-adaptive Prompting (COSP), a novel prompt design method for LLMs. Requiring neither handcrafted responses nor ground-truth labels, COSP selects and builds the set of examples from the LLM zero-shot outputs via carefully designed criteria that combine consistency, diversity and repetition. -
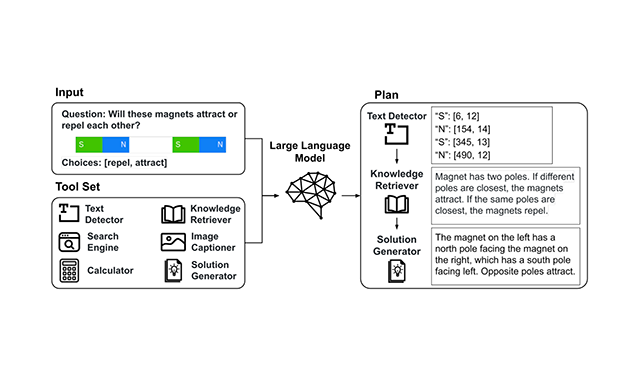 Tool Documentation Enables Zero-Shot Tool-Usage with Large Language ModelsTool documentation—individual tool usage descriptions—is an alternative to LLM demonstrations. We demonstrate that zero-shot prompts on a tool-use dataset with hundreds of available tool APIs or with unseen state-of-the-art models as tools achieve better performance compared to few-shot prompts.
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language ModelsTool documentation—individual tool usage descriptions—is an alternative to LLM demonstrations. We demonstrate that zero-shot prompts on a tool-use dataset with hundreds of available tool APIs or with unseen state-of-the-art models as tools achieve better performance compared to few-shot prompts. -
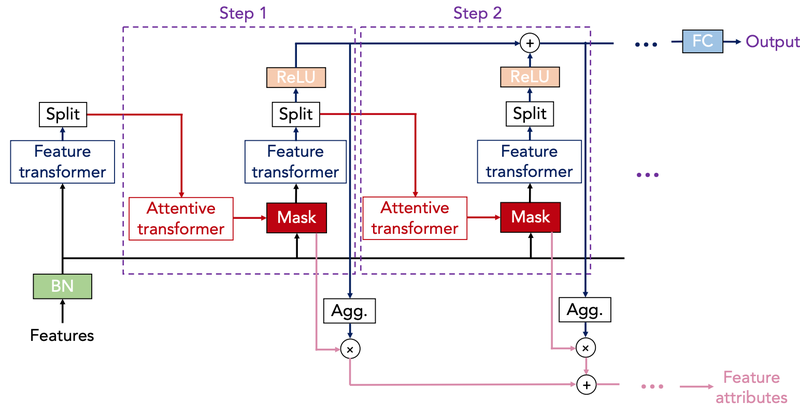 TabNetA new deep learning method for tabular data that improves over other DNN and ensemble decision tree models on many datasets and provides interpretable insights.
TabNetA new deep learning method for tabular data that improves over other DNN and ensemble decision tree models on many datasets and provides interpretable insights. -
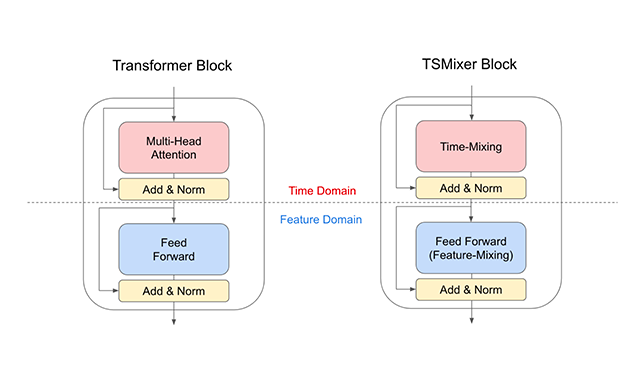 TSMixer: An all-MLP architecture for time series forecastingA new multivariate model that leverages linear model characteristics and performs well on long-term forecasting benchmarks.
TSMixer: An all-MLP architecture for time series forecastingA new multivariate model that leverages linear model characteristics and performs well on long-term forecasting benchmarks. -
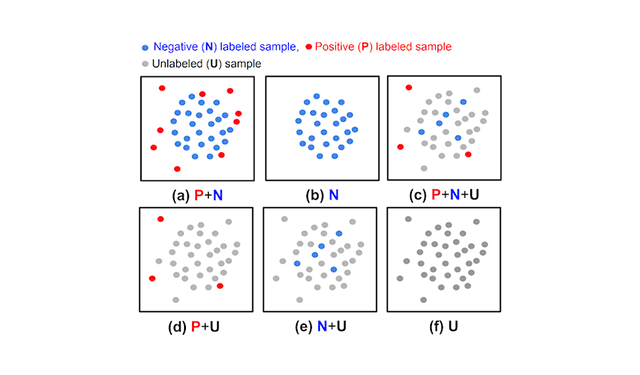 Unsupervised and semi-supervised anomaly detection with data-centric MLAn anomaly detection method that utilizes an ensemble of OCCs to estimate the pseudo-labels of unlabeled data independent of the given positive labeled data, thus reducing the dependency on the labels.
Unsupervised and semi-supervised anomaly detection with data-centric MLAn anomaly detection method that utilizes an ensemble of OCCs to estimate the pseudo-labels of unlabeled data independent of the given positive labeled data, thus reducing the dependency on the labels.
Some of our locations

Some of our people
-

Tomas Pfister
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +1 more
-

Alex Muzio
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
- +3 more
-

Chen-Yu Lee
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Chun-Liang Li
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +1 more
-

Hootan Nakhost
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Jinsung Yoon
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +1 more
-

Lesly Miculicich
- Machine Intelligence
- Machine Translation
- Natural Language Processing
-

Long T. Le
- Data Mining and Modeling
- Machine Learning
- Natural Language Processing
-

Rajarishi Sinha
- Algorithms and Theory
- Machine Intelligence
- Machine Translation
- +1 more
-

Ruoxi Sun
- Data Mining and Modeling
- General Science
- Machine Intelligence
- +1 more
-

Sayna Ebrahimi
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
-

Sercan O. Arik
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
- +2 more
-

Yanfei Chen
- Machine Intelligence
- Natural Language Processing
-

Yihe Dong
- Algorithms and Theory
- Natural Language Processing
-

Zifeng Wang
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
